AI Powered Code Review Tools
You've been vibe coding. Cursor wrote the auth layer. Claude Code scaffolded the API. It looks reasonable. But Veracode's 2025 GenAI Code Security Report found that AI-generated code contains 2.74x more vulnerabilities than human-written code — testing over 100 LLMs across four languages. If you're building with a vibe coding tool, code review isn't optional — it's the quality gate that validates what autonomous generation produced.
The problem isn't that AI writes bad code. The problem is that nobody's reviewing it properly.
Generic AI code review tools don't solve this. "Use parameterized queries" is technically correct. It doesn't tell you which file. It doesn't know your ORM. It doesn't know your data access layer is structured in a way that makes half those warnings irrelevant and the other half critical. It's a checklist wearing a UI.
Tekk's Expert Review Mode reads your actual codebase first. Then it searches the web for current best practices specific to your stack. The recommendations you get back aren't generic — they're grounded in your files.
[Try Tekk.coach Free →]
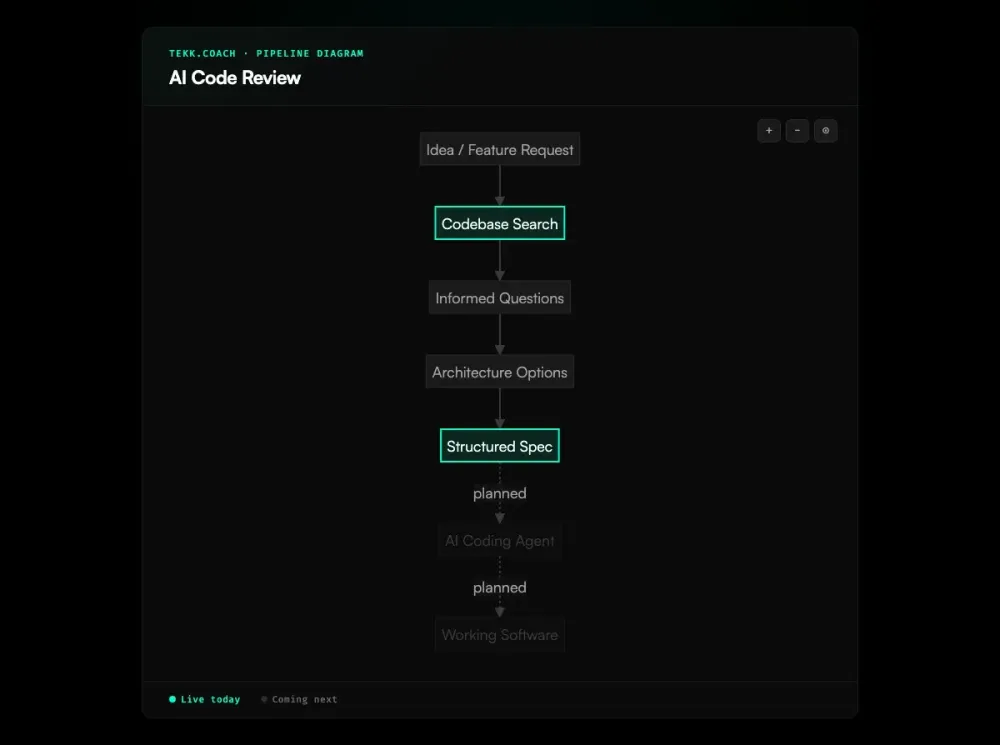
How Tekk.coach Does AI Code Review
Tekk runs four types of reviews, each one grounded in what's actually in your repo.
Security review Not an OWASP checklist. The agent reads your authentication layer, your database queries, your API surface, and finds real issues: exposed secrets, injection points, missing authorization checks, insecure data handling. It tells you what's wrong and where. This matters because injection vulnerabilities are the single most common flaw in LLM-generated code, appearing in 16 of 20 studies in a systematic literature review.
Architecture review Bad patterns compound. The tight coupling you introduced in week two becomes structural by month three. Tekk's architecture review surfaces those patterns before they get load-bearing — dependency tangles, missing abstractions, brittle data models — and tells you what to refactor before it becomes a rewrite.
Performance review N+1 queries, blocking operations in async code, missing indexes, unnecessary recomputation. These don't fail tests. They show up in production. The performance review finds them first.
Agent improvement If you're building with Cursor, Claude Code, or Codex, your agent setup is part of what needs reviewing. Are your prompts grounded in your actual codebase? Is your context window being used well? Are your workflows structured for reliability? Nobody else is reviewing this. Tekk does. Spec driven development is the practice that structures those agent inputs — and the agent improvement review tells you whether your current workflow is close enough to that standard.
After every review: the agent reads your code, searches the web for current best practices for your specific stack, and delivers recommendations tied to your actual files. If you're using Drizzle ORM with PostgreSQL, you get Drizzle-specific recommendations — not generic SQL advice that could apply to any app ever written.
Key Benefits
Grounded in your code, not a template Tekk reads the repo before it says anything. Every finding connects to a real pattern in your codebase. No vague warnings that leave you hunting.
Four dimensions in one review Security, architecture, performance, agent improvement. Most AI code review tools do one of these well. Tekk runs all four from the same codebase read.
Current best practices, not stale training data The review agent searches the web during the review. Your recommendations reflect what the field knows now, not what was in a dataset a year ago. As Addy Osmani argues in Code Review in the Age of AI, changes should ship with evidence — manual verification and automated tests — not just a clean diff.
Expert-level output, no consultant required A security audit runs into the thousands and takes weeks. An architecture review from a senior engineer costs more. Tekk's review takes minutes. It won't replace a dedicated expert engagement, but for most solo founders and small teams, it catches what matters.
How It Works
- Connect your repo — GitHub, GitLab, or Bitbucket.
- Choose a review type — security, architecture, performance, or agent improvement.
- Agent reads your codebase — semantic search, file search, regex, directory browsing, full repo profiling. It builds an actual picture of your system.
- Agent searches the web — current best practices for your stack, framework, and version.
- You get specific recommendations — not "consider using parameterized queries." Your query. Your file. Your fix.
Who This Is For
Vibe coders who want to trust what they shipped You built fast. AI wrote most of it. You're not certain the auth is actually secure. The security review tells you.
Solo founders without a security expert You don't have one on the team. You probably won't for a while. Tekk is the review that would otherwise skip. Ai code review for solo developers covers exactly this gap — security, architecture, and performance review without needing a senior engineer on the team.
Small teams with no dedicated architect Three engineers, a growing codebase, technical debt you can feel but not quite see. The architecture review names it.
Anyone shipping with AI coding agents CodeRabbit's analysis of 470 GitHub PRs found that AI-generated PRs contain 1.7x more issues than human-written ones — including 8x more performance inefficiencies. The faster you ship with these tools, the more important the review becomes. Tekk was built for exactly this workflow.
What Are AI Powered Code Review Tools?
AI powered code review tools use large language models and static analysis to evaluate source code for security vulnerabilities, quality issues, architectural problems, and bugs — automatically, at the speed of development.
The category grew out of legacy static analysis tools like SonarQube and ESLint. Those tools flagged rule violations. They couldn't explain why something was wrong, suggest a fix in plain English, or understand the broader system. Modern AI review tools do all three.
The current landscape:
- CodeRabbit — PR-integrated; 2M+ connected repos, 13M+ PRs processed; works across GitHub, GitLab, Bitbucket, Azure DevOps
- GitHub Copilot Code Review — editor-integrated; reached 1M users within a month of GA in April 2025
- Cursor BugBot — PR review with autofix; 76% resolution rate; 2M+ PRs reviewed monthly
- Snyk Code — security-focused; exact-line findings with fix suggestions
- SonarQube — mature static analysis; 30+ languages; standard in enterprise CI/CD
- Greptile — deep codebase-context analysis; enterprise-focused at $30/dev/mo
Most of these tools focus on the pull request — reviewing the diff, not the whole system. They're good at catching regressions. They're less suited to structural health checks or reviewing how your AI agent setup is configured. For a broader overview of how AI is reshaping code review workflows, GitHub's official guide covers the fundamentals.
The vibe coding problem Vibe coding — prompting AI, accepting output, iterating by prompt rather than by understanding — went mainstream in 2025. It produces code fast. It also produces vulnerable code at scale: a December 2025 analysis of five vibe coding tools found 69 security vulnerabilities across 15 generated applications. AI-authored PRs contain 1.7x more critical and major issues than human-written ones, with performance inefficiencies appearing nearly 8x more often.
Code review has always mattered. When AI writes the code, it matters more.
Frequently Asked Questions
What are the best AI powered code review tools? The most widely used are CodeRabbit (2M+ repos), GitHub Copilot Code Review (1M users within a month of GA), and Cursor BugBot (2M+ PRs monthly). For security-specific review, Snyk Code is strong. For enterprise static analysis, SonarQube is the standard. For codebase-level reviews that go beyond the diff — security posture, architecture health, performance bottlenecks, AI agent improvement — Tekk.coach is built for that.
What is an AI code review tool? An AI code review tool uses large language models to automatically analyze source code and identify issues — bugs, security vulnerabilities, architectural weaknesses, style problems — and explain them with suggested fixes. They range from PR comment bots (CodeRabbit, BugBot) to static analysis platforms (SonarQube, Snyk) to full-codebase review systems (Greptile, Tekk).
What is the best AI code review tool in 2026? Depends entirely on the use case. Automated PR review on every merge: CodeRabbit or BugBot. Security scanning in CI/CD: Snyk or CodeAnt AI. Codebase-level review of security posture, architecture health, performance, and agent setup: Tekk.coach. There is no single best tool — there's the right tool for what kind of review you actually need.
How does Tekk's AI code review differ from other tools? Most tools review the pull request diff. Tekk reads the entire codebase. It also runs web research during the review — finding current best practices specific to your stack — and connects those findings to your actual files. It covers four dimensions (security, architecture, performance, agent improvement) from a single codebase read. That combination doesn't exist elsewhere in the category.
What is vibe coding code review and why does it matter? Vibe coding means building software by prompting AI tools and shipping the output without deep review. It's fast and the results often look fine. It's also producing code with elevated vulnerability rates: AI-generated code introduces security flaws in 45% of cases (Veracode, 2025), and AI-authored PRs contain 1.7x more issues than human-written ones. Vibe coding code review is the practice of validating that output before it ships. Tekk's Expert Review Mode was built for this.
Does Tekk do security reviews on AI-generated code? Yes. The security review reads your codebase — including code written by Cursor, Claude Code, or any other AI tool — and finds real vulnerabilities: exposed secrets, injection points, missing auth checks, insecure data handling. It searches for current best practices specific to your stack and delivers findings tied to your actual files.
How is Tekk's AI code review different from GitHub Copilot's review features? Copilot Code Review is editor-integrated and PR-focused. It's good at catching obvious bugs and style issues in the diff. Tekk reads the whole codebase, runs web research during the review, covers four review dimensions instead of one, and is built for the vibe coding workflow — where the question isn't "is this PR clean?" but "is the system I've been building over the last three months actually sound?"
Your AI-Generated Code Needs a Review
Vibe coding is how software gets built in 2026. That's not a problem. Shipping it without any review is.
Tekk reads your codebase and tells you what's actually wrong — security holes, structural issues, performance bottlenecks, agent setup problems. Specific findings. Your files. Your stack.
[Start Planning Free →]